I wrote about the Elite game protection on RISC OS a while back and showed a way of bypassing it by using a custom module to edit the machine code in memory. At the time I said I couldn’t be bothered to reverse engineer how it stores the words.
It’s time to revisit. We’ll use the same techniques as before, using !Hacker from Doggysoft to interrupt the game when we’re entering a word, although we can save some time as we know the rough memory locations.
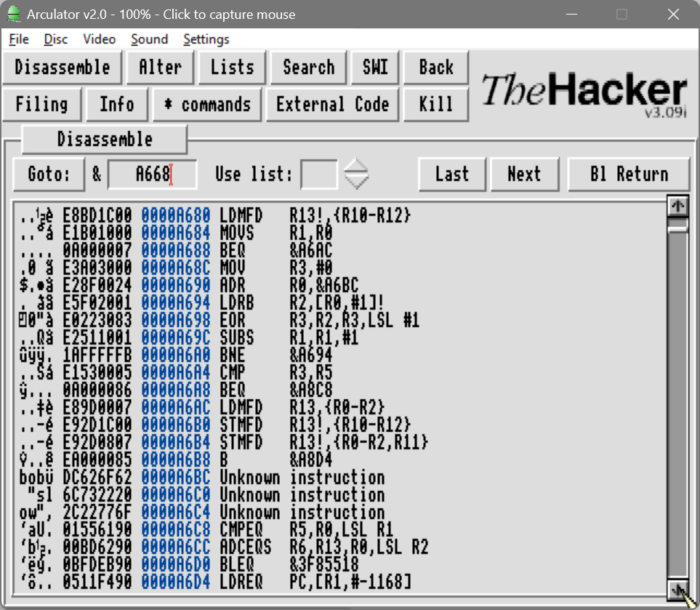
We know that the input word is stored in memory location &A6BC and that the code that accesses this area of memory is at &A668 and &A690.
If we go to &A668 we can see what looks like the parameters to a call to input from the keyboard:
ADR R0,&A6BC
MOV R1,#&B
MOV R2,#&41
MOV R3,#&7AIf we assume the input buffer is at &A6BC, then R1 is set to 11 – i.e. the length of the buffer. R2 is set to &4A, i.e. "A" and R3 is set to &7A, i.e. "z". Somewhere in the code will be a call to validate and filter the inputted characters and convert the case to either upper (AND #&DF) or lower (OR #&20) case.
We already know the &A690 contains the code to check the inputted word, and we’ll look at this a bit more in-depth later. For now we can have a look at the buffer, at &A6BC. We can see three 32-bit words of junk, including the letters "slow". Then we have a number of 32-bit words, starting from &A6C8, which aren’t code, but have a similar pattern, these are potentials for storing the words from the manual.
One side effect of adding copy-protection, is that it usually isn’t built as part of the game. Whether to make it easier to test the game, or because it’s usually added at the end of the creation process; copy protection is added on at the end, which means it’s usually in the same place in memory.
If we scroll up a bit from this location we can see &A6C8 referenced at &A60C. The code here is interesting, it’s taking a 32-bit word, and then AND off the lower few bits and then shifting it. It does this four times, leaving the left-over in R5. If we remember from the word test routine, the final check is against R5.
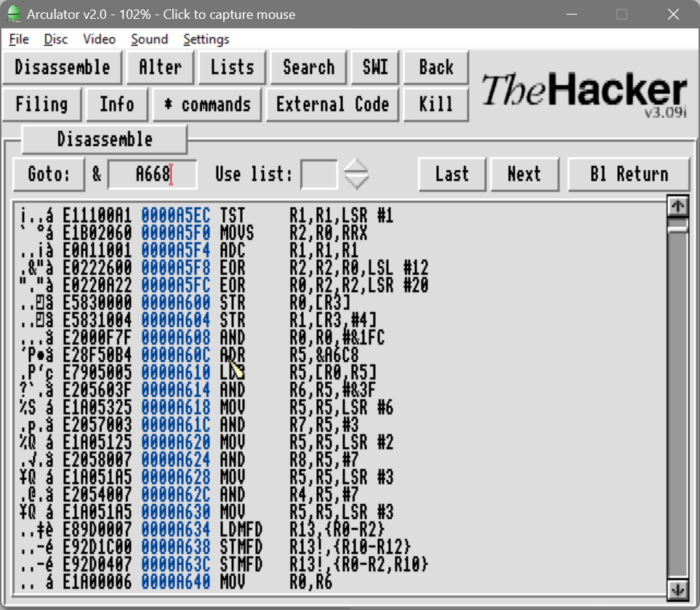
So it looks like it carves the 32-bit word into 5 sections; this matches with the page, paragraph, line and word of the page presented. The remaining section is probably the hash. Assuming this is the format we can repeat this programmatically with a bit of Python:
def breakup(value):
page=value & 0x3f
value = value >> 6
paragraph=value & 3
value = value >> 2
line = value & 7
value = value >> 3
word = value & 7
result = value >> 3
return (page, paragraph, line, word, result)Applying this to the first value at &A6C8, which is &01556190 then we get:
Page: 16
Paragraph: 2
Line: 3
Word: 5
Hash: 12279Looking for an Elite manual online, then this word is strongly.

Let’s revisit the hashing algorithm and implement it in Python. The algorithm is at &A690, where it loads the characters from the input buffer and does an XOR with a shift, then XORs the next character and repeats until the end of the string:
ADR R0,&A6BC
LDRB R2,[R0,#1]!
EOR R3,R2,R3,LSL #1
SUBS R1,R1,#1
BNE &A694This can be converted to Python as:
def hash(string):
string += "\x0d"
result=0
for l in range(1,len(string)):
result=ord(string[l]) ^ (result << 1)
return resultIf we run this with the word strongly we get a result of 12279! So we can now map all the possible words that it could choose and the hash that could map; or just spend about an hour retyping them words from the manual to a document.
But there’s some errors in the hashing algorithm. The LDR is interesting for two reasons:
- It does a LDRB which loads a byte into R2, as all 32-bit ARM registers are 32-bit, this means the top 3 bytes will be zero
- The offset is set to #1, and it updates the base register (R0). This means that it will skip the first character in the string
- As it still follows the length of the response and it skips the first character, that means the last character will always be
&0D– i.e. a CR
So we can reduce the entropy a bit by manipulation. Entering strongly or ttrongly will both work. As some words are only 4 characters, this makes it easier to guess. The hashing function is quite simple, so different words could match the same hash. Finally, as the algorithm included a left shift, and the XOR only occurs on the bottom byte, then the length of the hash will be relative to the word.
We can also now make an exhaustive list of all possible words – going back through the memory within !Hacker show that the are only 128 possible words (from &A6C8 to &A8C8). We can *SAVE the memory and extract all the data. Then is we dump all the words from the manual, we can precalculate a matching word from to create a dictionary.
Finding a the Elite manual online and throwing it through a free OCR program is relatively simple. I wrote a bit of Python to prepopulate a dictionary, taking the words I extracted from the manual. This got all but two words which had OCR errors.