I’ve been digging into more MZ-700 games to try and extract data to view and parse it. One I was passed was called Three Crystals. It was a BASIC text adventure that loaded all its data from tape (a 7 minute load)!
The current MZF format doesn’t support the BASIC data format, this means that it has to be downloaded as a .MZF for the BASIC program and a .WAV for the data.
Using my detokeniser to extract the BASIC program shows it being loaded:
220 ROPEN:CLS:CURSOR8,10:PRINT"Loading Data - 7 MINUTES"
230 DIMRN$(164),D$(164),EX$(164),N$(90),V$(46),IT(90),P$(25)
240 BA=$2EC0:FORV=1TO46:READV$:V$(V)=V$:POKEBA,ASC(LEFT$(V$,1)):POKEBA+1,ASC(MID$(V$,2,1)): POKEBA+2,ASC(MID$(V$,3,1)):POKEBA+3,V:BA=BA+4:NEXT:POKEBA,42:POKEBA+1,42:POKEBA+2,42:POKEBA+3,0:GOSUB4000
250 CURSOR7,19:PRINTPW$
260 FORX=1TOTX:INPUT/T RN$(X),D$(X):NEXT
270 FORX=1TONC:INPUT/T N$(X):NEXT
280 CURSOR7,19:PRINT"QUICK DISC for a fast load"
290 FORX=0TO25:INPUT/T P$(X):NEXT
300 CURSOR7,19:PRINTPW$ROPEN is the MZ-700 BASIC command to open a cassette data file; INPUT/T is the command to input a value from the data file into a variable.
But how is this data stored on tape; lets have a quick look at the wav file:
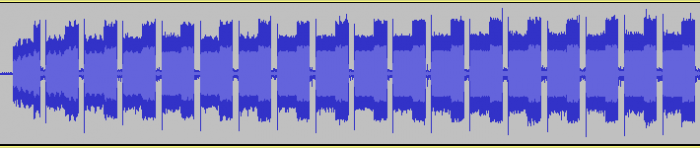
Here we can see lots of smalls blocks of data; zooming into the first block show an LGAP, but with some weak signals and not quite complete. This is okay as the monitor only needs 100 short pulses to count an LGAP, what is important is the LTM following, which should be 40 long and 40 short pulses:

This indicates that this is a header. Some initial attempts to read caused a few problems as this WAV hasn’t been cleaned up and contains some problems with my previous routine to read bits. Before I took a bit from the rising edge above the centre pitch, but sometimes in the raw files you got waveforms like:
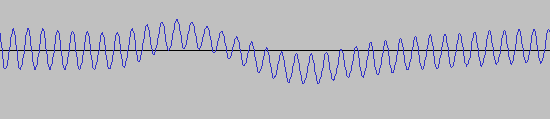
Which would get ignored. I needed to work out a new route. The emulator emuz-700 has a method for normalising the wave form by moving the wave forms to a normalised average. I tried implementing something similar but it was hard to get a stable result.
In the end I revisited my algorithm. Passing a specific threshold isn’t important – what is is making sure that there’s more samples between the minima and maxima of a waveform for a short pulse (in red) than for a long pulse (in green):
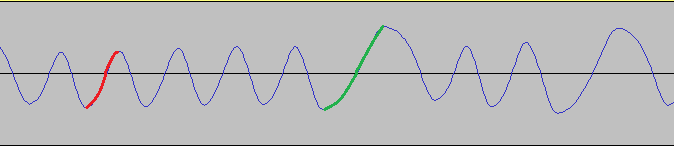
Finding a minima is easy – just increase a point until you find a point that is greater then your current one. Then count the number of samples until you find the next maxima. If this is more than a value (15 for 44 kHz) then it is a long pulse, otherwise it’s a short pulse.
To reduce the effect of noise, I also made sure that the amplitude between a minima and a maxima was greater than a threshold. This function is a bit more complex than before, but it is still relatively simple:
def read_pulse(wfile, skip):
value=0
repeat=True
try:
while repeat:
# look for the minima - i.e. the value is > the last one
ovalue=wfile.readframes(1)[0]
read_edge=wfile.readframes(1)[0]
while read_edge <= ovalue:
ovalue=read_edge
read_edge=wfile.readframes(1)[0]
# now count the frames to the maxima
minima=ovalue
fcount=0
ovalue=read_edge
read_edge=wfile.readframes(1)[0]
while read_edge >= ovalue:
fcount+=1
ovalue=read_edge
read_edge=wfile.readframes(1)[0]
maxima=ovalue
if (maxima - minima) > threshold:
repeat=False
if fcount > skip:
value=1
except:
# end of stream
value=-1
return valueThis worked quite well, although there were a few times when noise peaked during the gaps between blocks that I had to manually edit out by inserting silence, such as. But this is quite quick to do, by selecting troublesome space and then using Generate -> Silence from with Audacity.

Now I have a decent read mechanism which is quite robust, I could start to work out what data was on the tape file. The first block is a file header:
Header for first file
Type: MZ-700 data
Filename: DATA
Size: $0000
Load: $0000
Exec: $0000
Comment: bytearray(b'\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00')The file is of type MZ-700 data, which follows what we saw in the BASIC program; note that the size is blank. I had great difficult working out how this was stored, the commands are documented in the manual and a number of other books; but the format isn’t. There was one statement from Inside the MZ-700 (for which I have a physical copy) that it used blocks.
I noticed that it the subsequent blocks all started with an SGAP followed by an STM; implying they’re files and were very short. Twiddling a bit with settings showed me that each block was 258 octets in size:
- A 16-bit (two octets) integer showing the block offset – this can be safely ignored, except on the last block where it is $FFFF
- 256 octets of stored data. Unlike the BBC Micro OPENOUT format, all data is stored as strings, conversion to and from numbers takes place when it is written or read
I added a separate function to read datafiles, which just loops and reads data, including all the file gubbins (SGAP, STM, CHKF, S256 and the backup of everything) and then merges it together to output it as raw data.
There are two files on the tape, both data files:
- The data file which contains partial tokenised strings
- The setup file which contains the starting values of various counters and objects
For bonus points I also wrote a parser for the data file which will detokenise the strings.

These scripts have been releases on a github repository; with read_t2e.py being the tape reader and read3crystaldata.py is the parser of three crystals data file to return all the room descriptions.